Mongo Engine Bit by Bit
My notes on the Mongo Internals video by Mathias Stearn.
Sample file structure:
brmallya-MacBook:db agupta$ ls -halS /data/db/test*
-rw------- 1 505 wheel 128M May 9 2012 /data/db/test.1
-rw------- 1 505 wheel 64M Aug 3 2012 /data/db/test.0
-rw------- 1 505 wheel 16M Aug 3 2012 /data/db/test.ns
Mongo always keeps one empty file. So there always will be one partially empty and one completely empty file alocated by mongo. This is done so that you don’t have to pause and wait for the new file to get allocated, when the current file completely filled.
You can always tune this with parameters like --smallfiles, --noprealocate.
MMap
Maps a file on disk into memory(virtual memory not physical ram). So mongo is not a in-memory database.
Executables also use this technique to run in operating systems.
In journaling each file will be mapped twice.



Doubly Link list

.ns file (16 mB)
A giant hash table. 1 kb per bucket (represents a collection), i.e. 16000 namespaces per database. You can change the default size of namespace. Every collection and every index will get a place in name space. Index names are like collectionName.$.indexName. Every bucket will have following:
- stats : count, size etc
- First extent, Last Extent
- Deleted List[19]
- Index Data (Link to each of the indexes)
Deleted List: When a record is deleted, we take the size of record and get the deleted bucket index by dividing it with the power of 2. Every entry in deleted list will be a singly link list. When alocating new record we can find the nearest about same size record memory from the deleted list. Compact command is introduced to delete these holes. To find the compact size see the storageSize - lastExtentSize vs dataSize.
Then there is a special namespace $freelist. (??)

DiscLoc:
A pointer to a location on disk. It looks like:
struct DiskLoc {
int fileNum; //the 0 in test.0
int offest; //position in file
}; //64 bits
Max possible offset is 2^32 - 1, this is also the max file size.
Extent:
An extent is a contiguous block in single file that is directly owned by a single name space. Every extent will have following:
- myLocation
- next extent
- prev extent
- first record
- last record
- length with headers
- data (not to scale)
Extents are introduced to make data partially localized. This way only small portion of memory is loaded in the cache.
When a new extent is created, mongo creates a new very big deleted record and adds it to the deleted list.
Record:
A record contains:
- Length with headers
- extent 0fs (extent link in which it is present)
- next record
- prev record
- data (Not to scale, may be larger than object if padding > 1)
Padding: When a record, say a bson object of size 2k, is first inserted a Record is created with data size 2k. If you update it and make it 3k then this Record is moved to a different location but this time instead of allocating 3k with also keep some padding. Padding size is decided by padding factor which increases on every update. The padding factors scope is collection level. Padding factor ranges from [1,2].
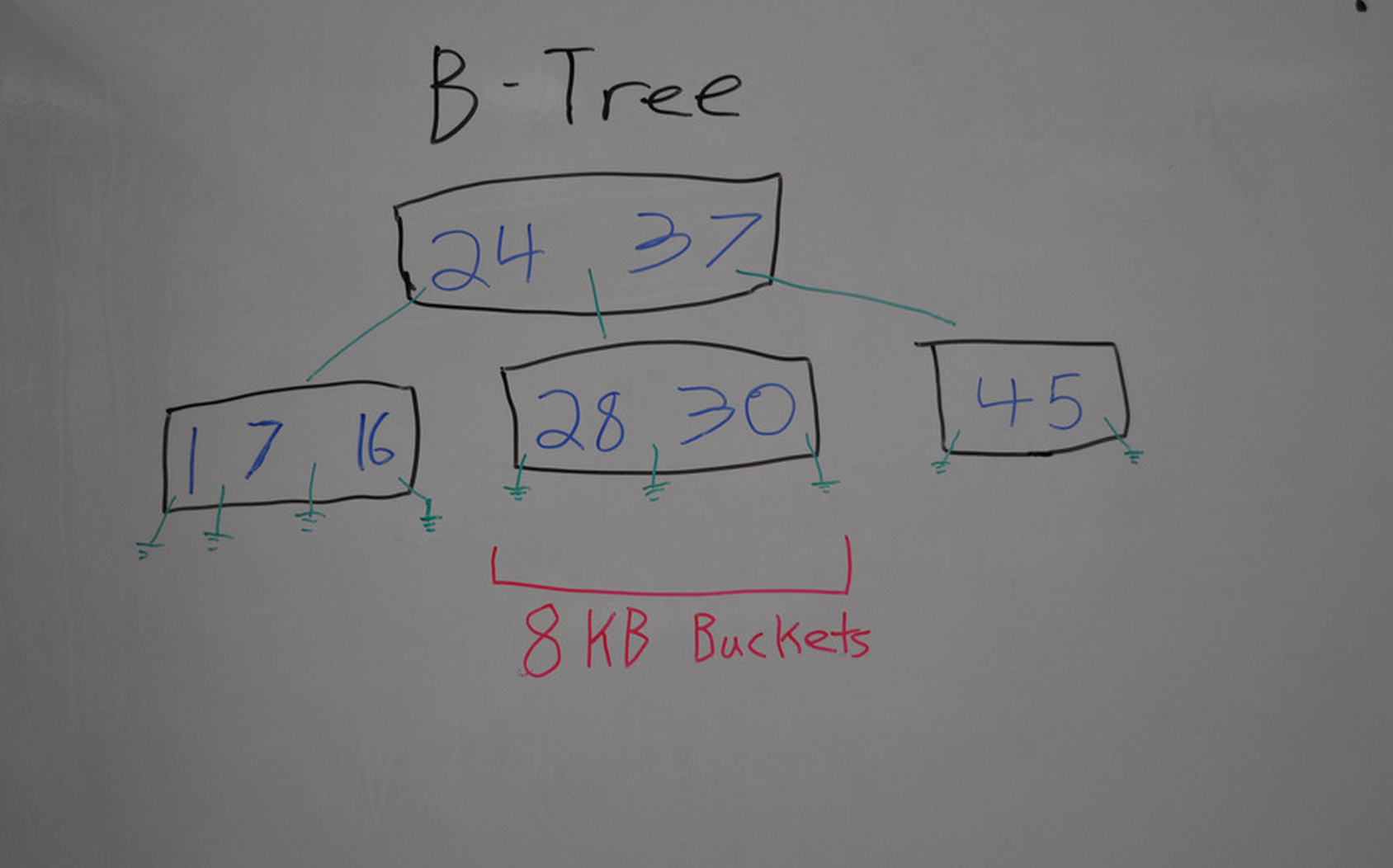
B-Trees:
A tree with fixed bucket size. If a bucket is full split it in two, with 50-50 data in each. But in mongo index the data is usualy incrementing as id has time parementer so for incrementing index mongo splits a bucket in 90% and 10% data bucket.